Obsah:
Spôsob 1: Použitie automatického nástroja
V Excel je automatický nástroj určený na rozdelenie textu do stĺpcov. Nepracuje v automatickom režime, preto všetky akcie bude potrebné vykonať ručne, predtým si vyberte rozsah spracovávaných údajov. Nastavenie je však maximálne jednoduché a rýchle na realizáciu.
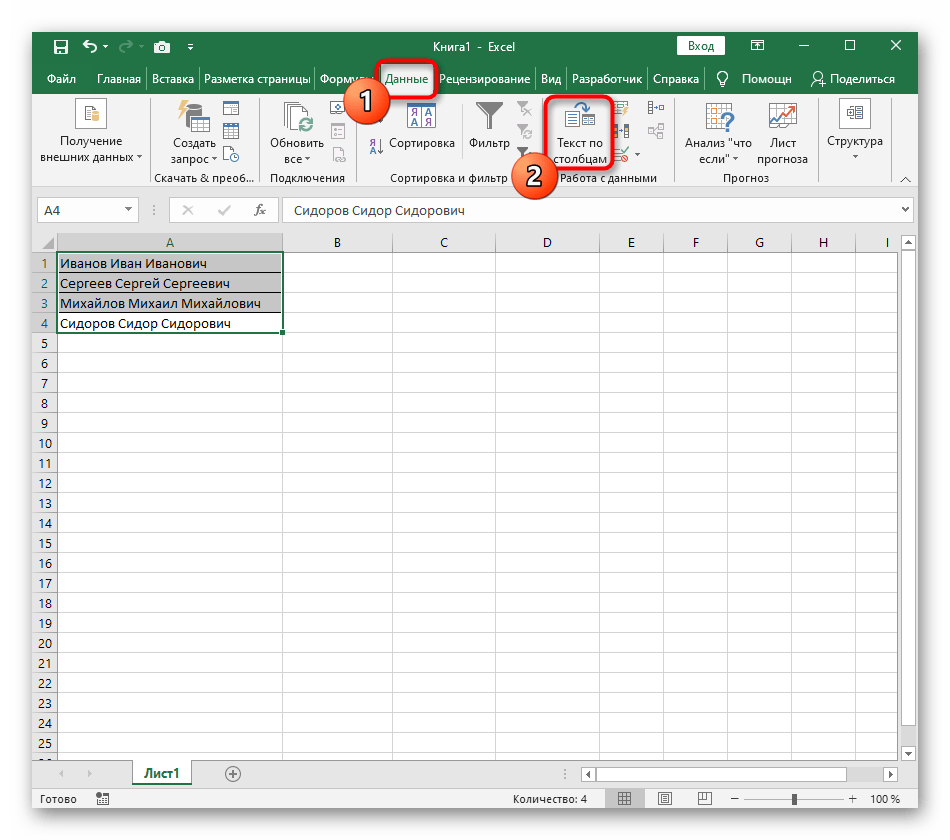
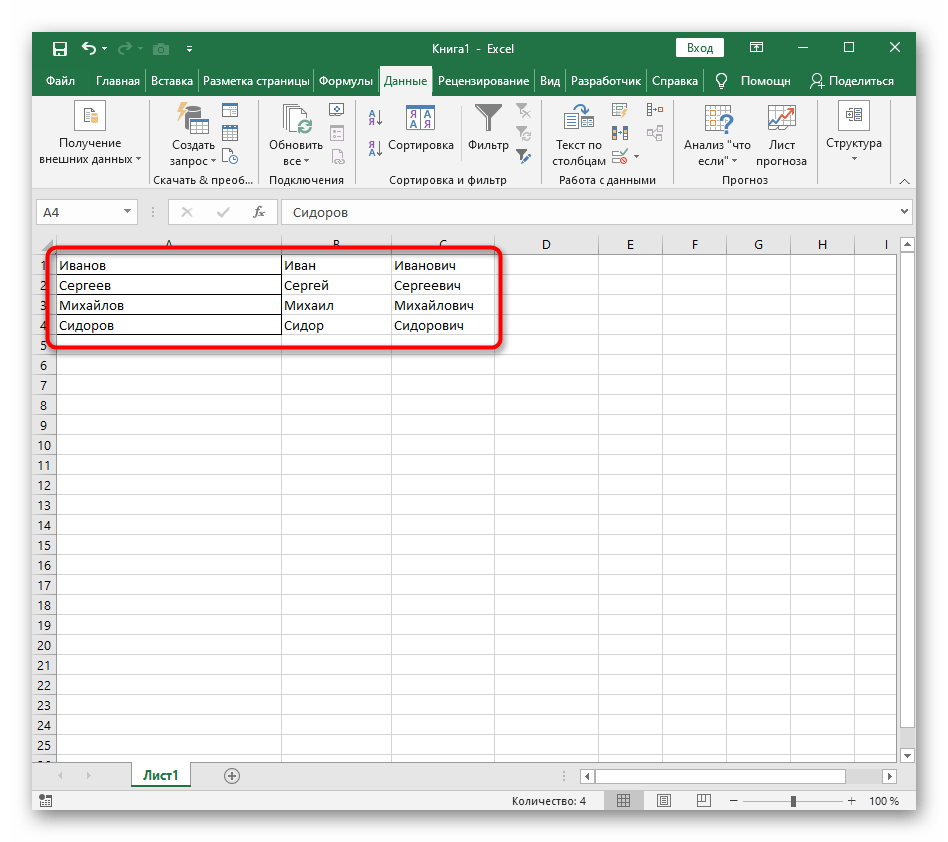
- S podržanou ľavou myšou vyberte všetky bunky, ktorých text chcete rozdeliť do stĺpcov.
- Potom prejdite na kartu "Údaje" a kliknite na tlačidlo "Text do stĺpcov".
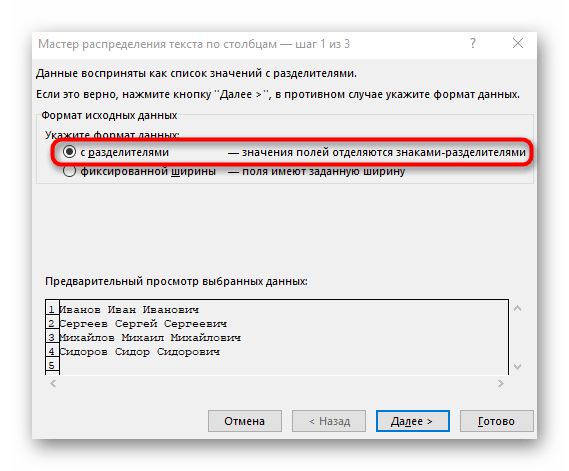
- Objaví sa okno "Sprievodcu rozdelením textu do stĺpcov", v ktorom je potrebné vybrať formát údajov "s oddeľovačmi". Oddeľovačom je najčastejšie medzera, ale ak ide o iný interpunkčný znak, bude potrebné ho uviesť v nasledujúcom kroku.
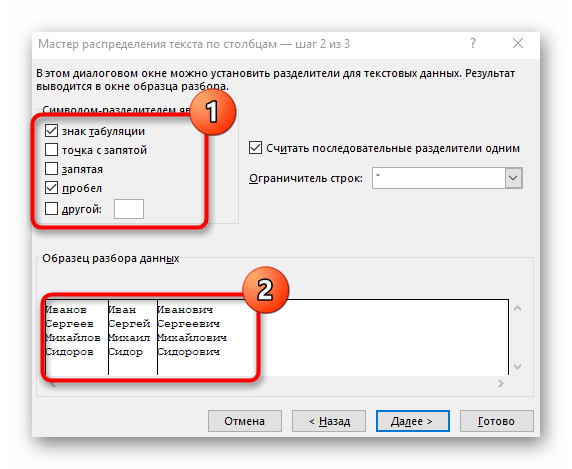
- Zaškrtnite symbol oddeľovania alebo ho manuálne zadajte a potom si prezrite predbežný výsledok rozdelenia v okne nižšie.
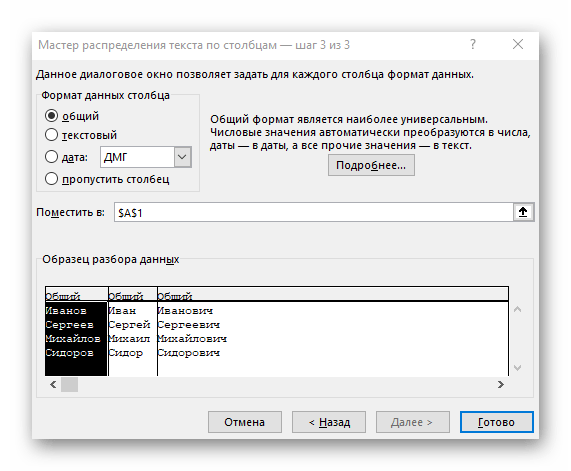
- V záverečnom kroku môžete uviesť nový formát stĺpcov a miesto, kam ich treba umiestniť. Akonáhle bude nastavenie dokončené, kliknite na "Hotovo" na aplikovanie všetkých zmien.
- Vráťte sa k tabuľke a uistite sa, že rozdelenie prebehlo úspešne.
Z tejto inštrukcie môžeme vyvodiť, že použitie takého nástroja je optimálne v situáciách, keď je potrebné rozdelenie vykonať len raz, pričom pre každé slovo označíte nový stĺpec.Avšak, ak sa do tabuľky neustále pridávajú nové údaje, bude nepraktické ich takto neustále rozdeľovať, preto v takýchto prípadoch navrhujeme oboznámiť sa s nasledujúcim spôsobom.
Spôsob 2: Vytvorenie vzorca na rozdelenie textu
V Exceli si môžete sami vytvoriť relatívne zložitý vzorec, ktorý umožní vypočítať pozície slov v bunke, nájsť medzery a rozdeliť každé na samostatné stĺpce. Ako príklad si vezmeme bunku pozostávajúcu z troch slov oddelených medzerami. Pre každé z nich bude potrebný svoj vzorec, preto rozdelíme spôsob na tri etapy.
Krok 1: Rozdelenie prvého slova
Vzorec pre prvé slovo je najjednoduchší, pretože sa bude vychádzať len z jednej medzery na určenie správnej pozície. Pozrime sa na každý krok jeho vytvorenia, aby sa vytvoril úplný obraz toho, na čo sú potrebné určité výpočty.
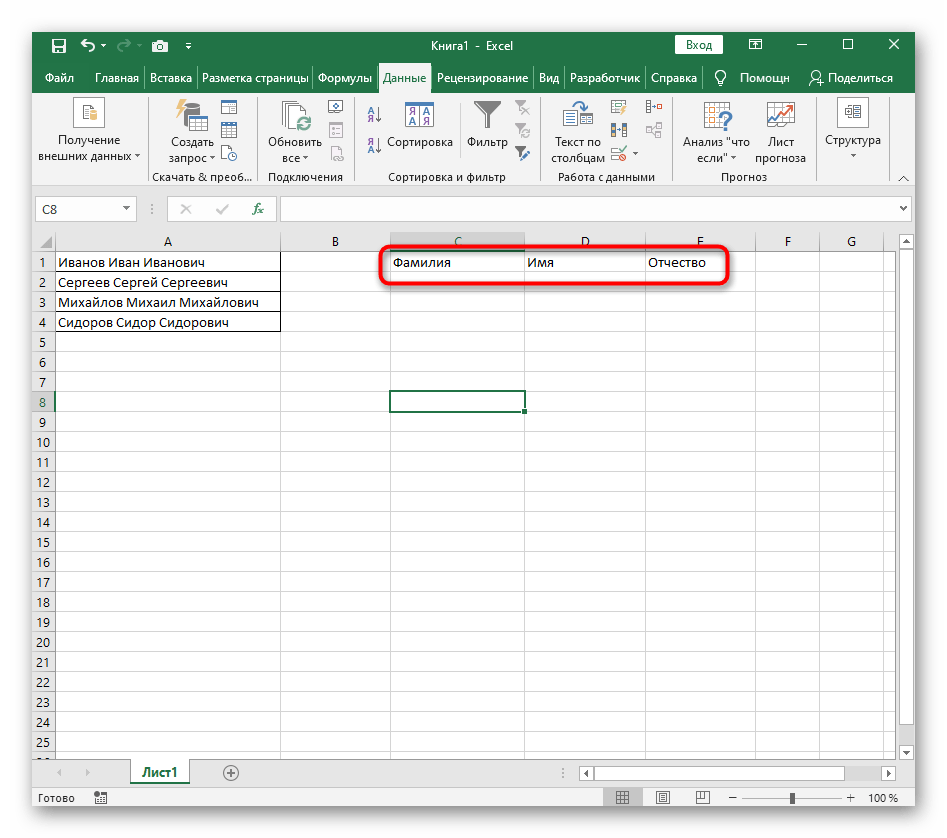
- Pre pohodlie vytvoríme tri nové stĺpce s popismi, kam budeme pridávať rozdelený text. Môžete to urobiť rovnako alebo tento krok preskočiť.
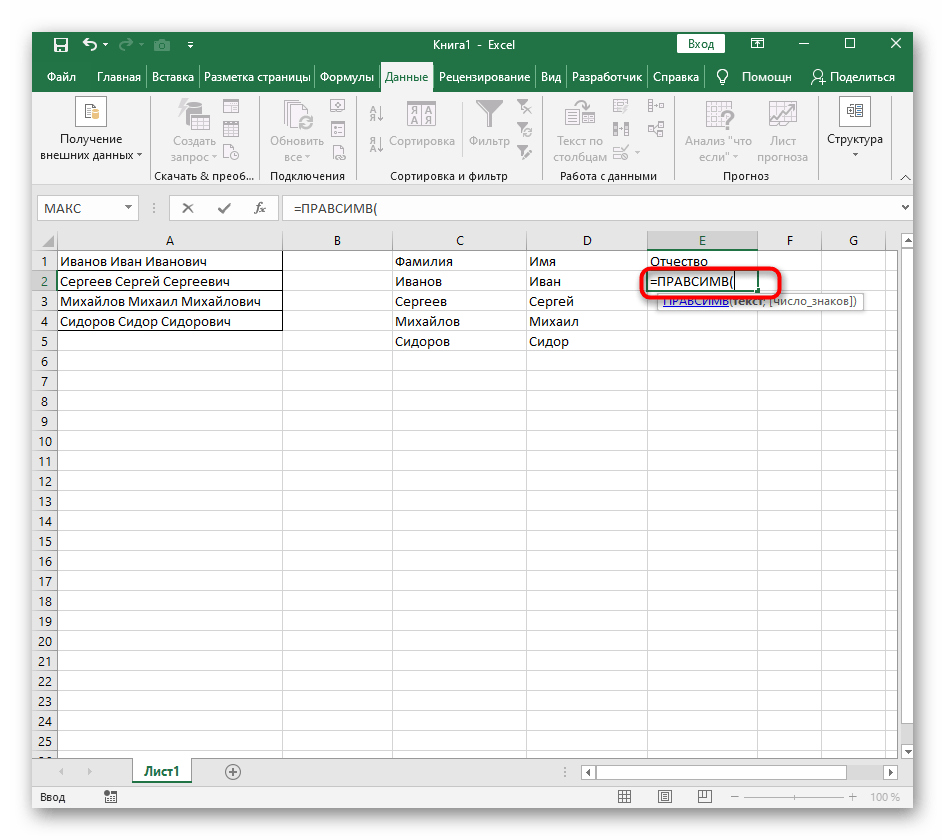
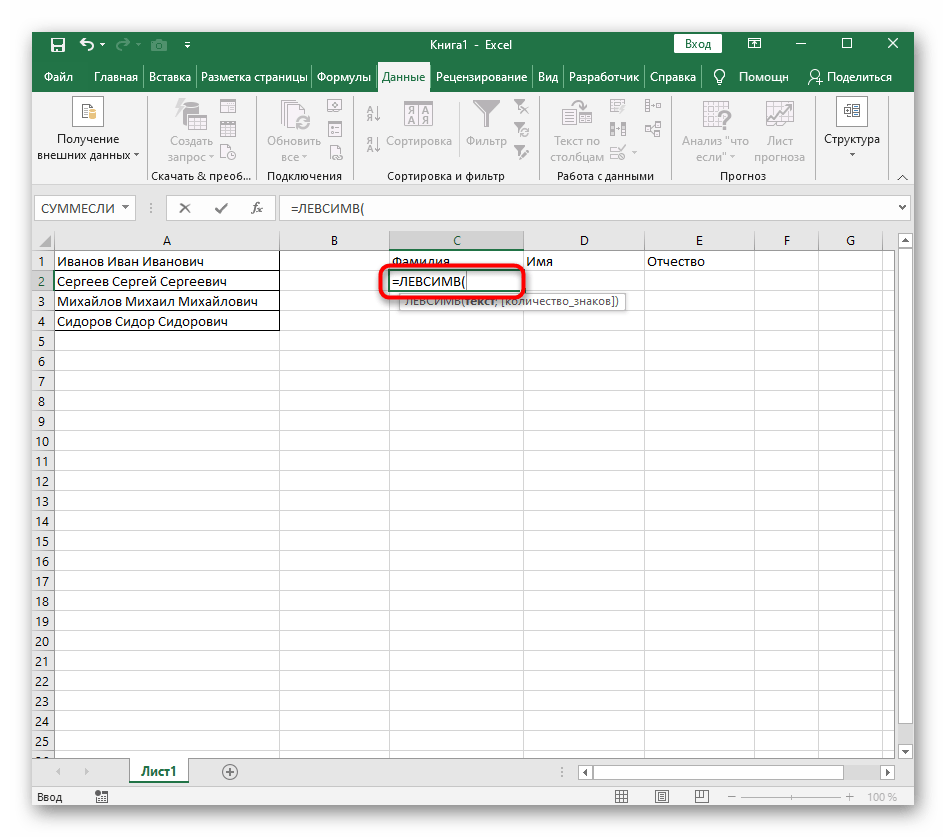
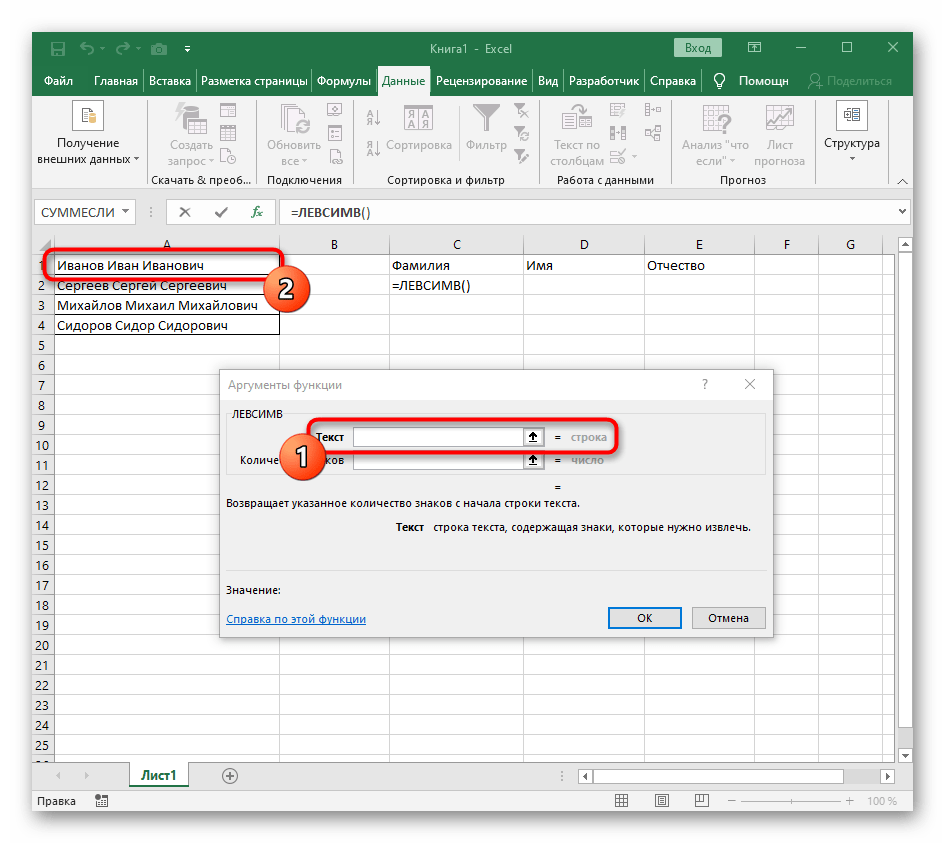
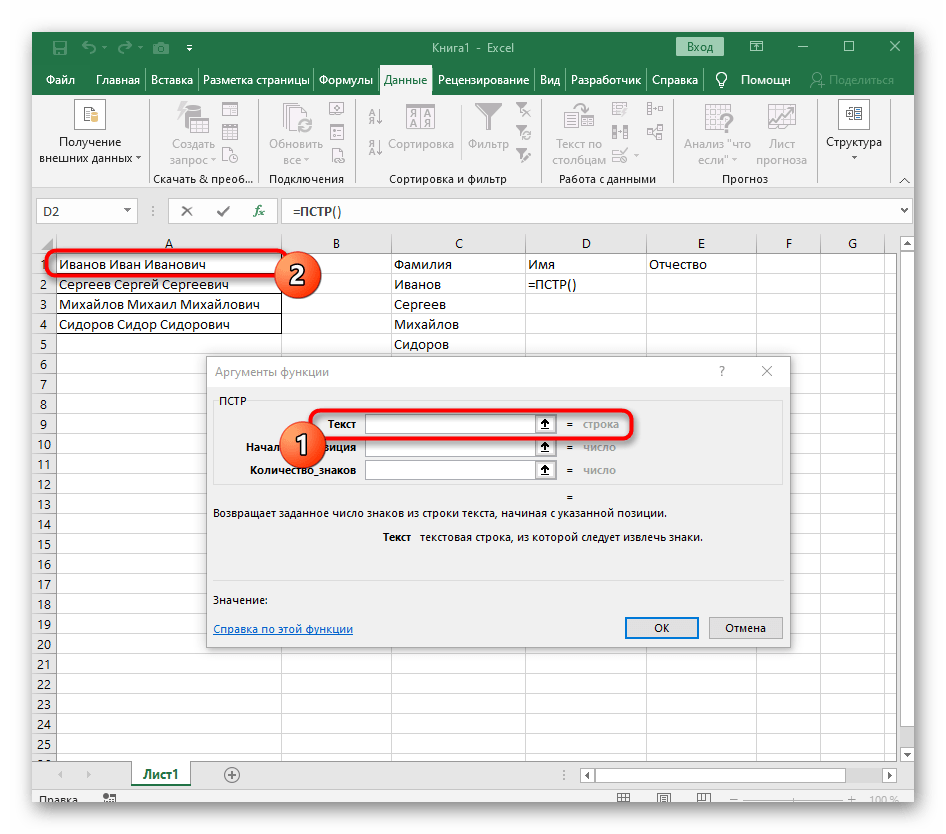
- Vyberte bunku, kde chcete umiestniť prvé slovo, a zapíšte vzorec
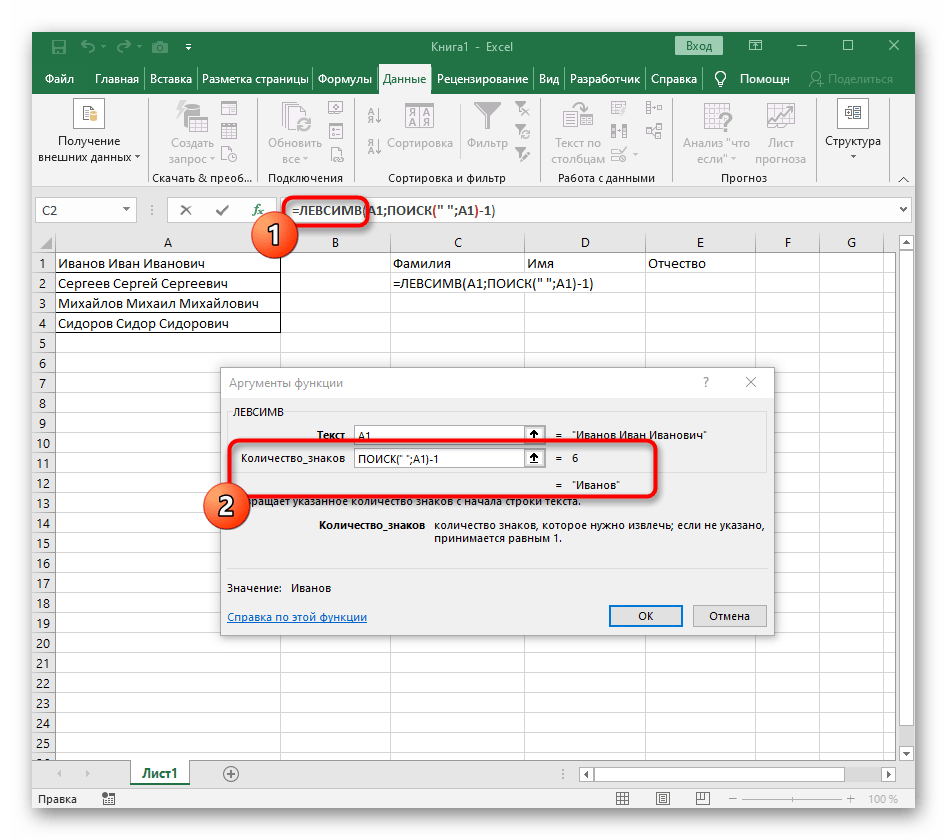
=ĽAVÝ(. - Potom stlačte tlačidlo "Argumenty funkcie", čím prejdete do grafického okna na úpravu vzorca.
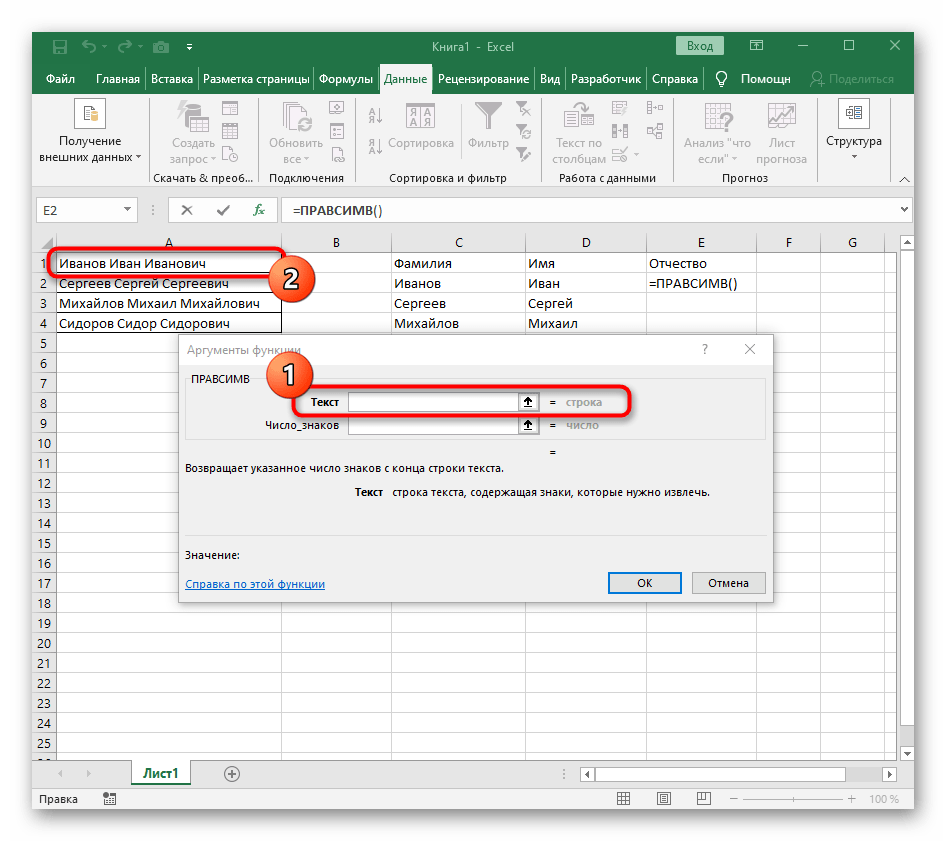
- Ako text argumentu uveďte bunku s nápisom, kliknutím na ňu ľavým tlačidlom myši v tabuľke.
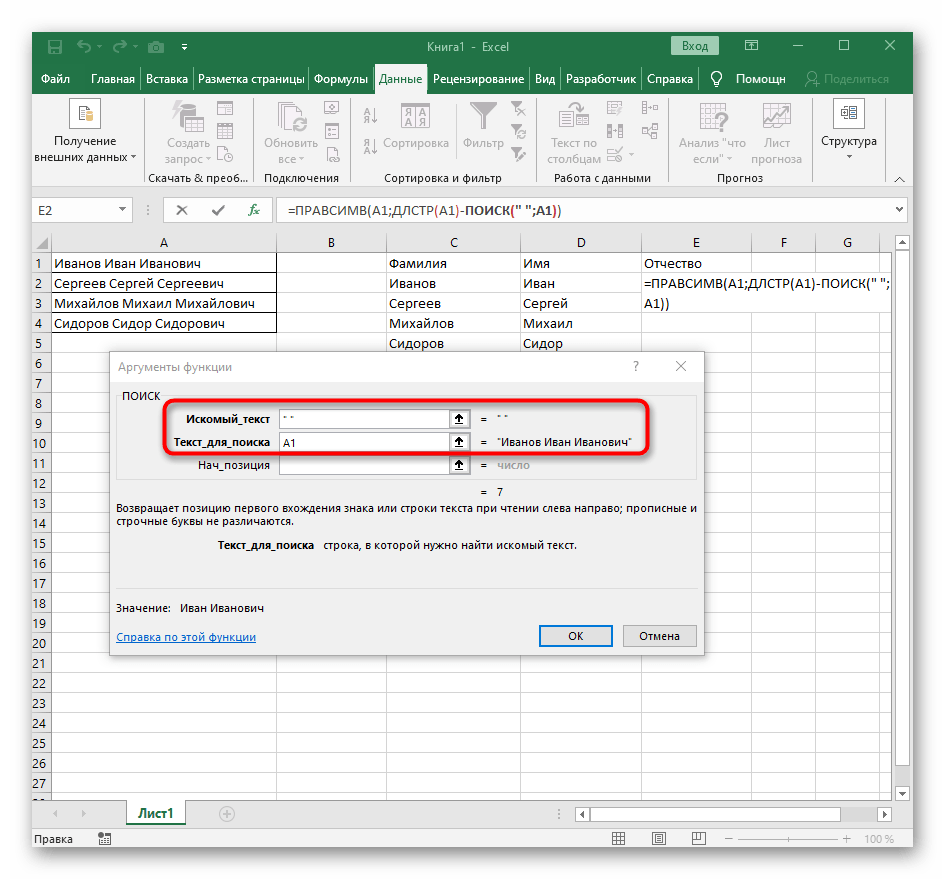
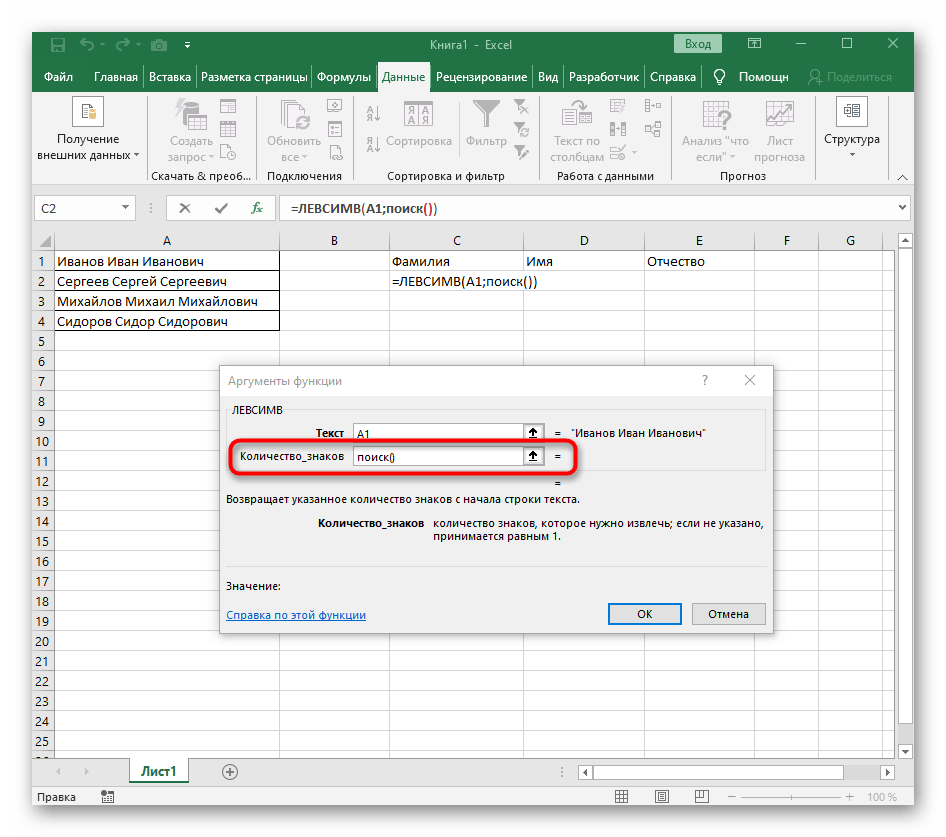
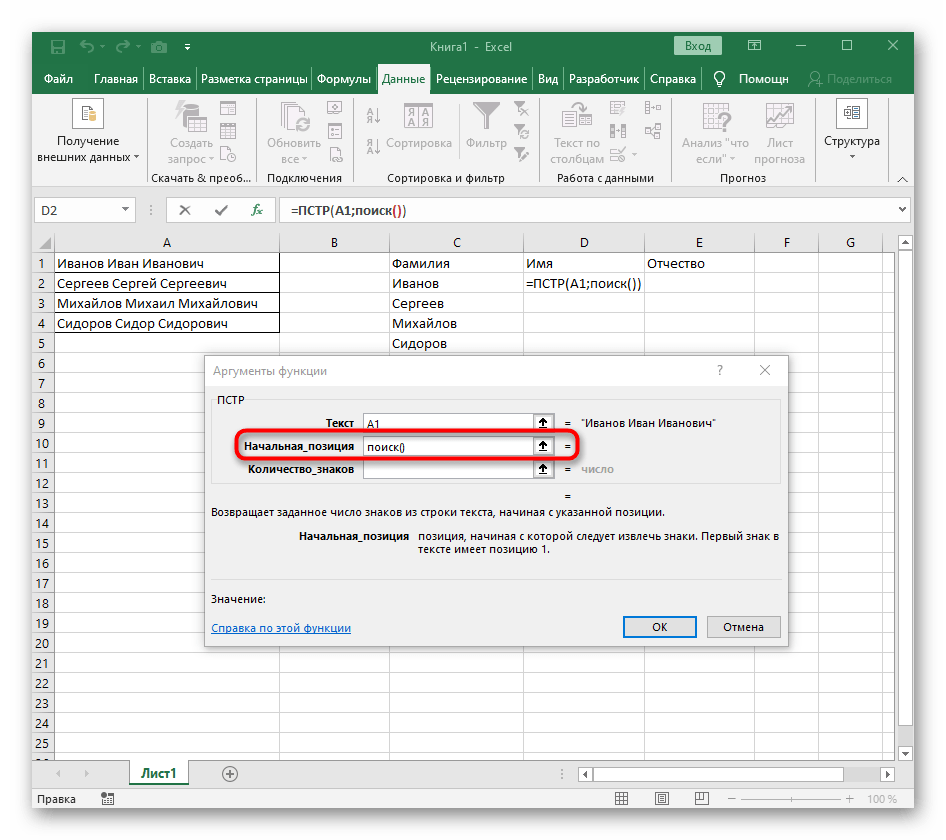
- Počet znakov pred medzerou alebo iným oddeľovačom bude potrebné vypočítať, ale manuálne to robiť nebudeme, ale využijeme ďalší vzorec —
NÁJDI(). - Akonáhle ho zapíšete v takom formáte, zobrazí sa v texte bunky hore a bude zvýraznený tučne. Kliknite na ňu pre rýchly prechod k argumentom tejto funkcie.
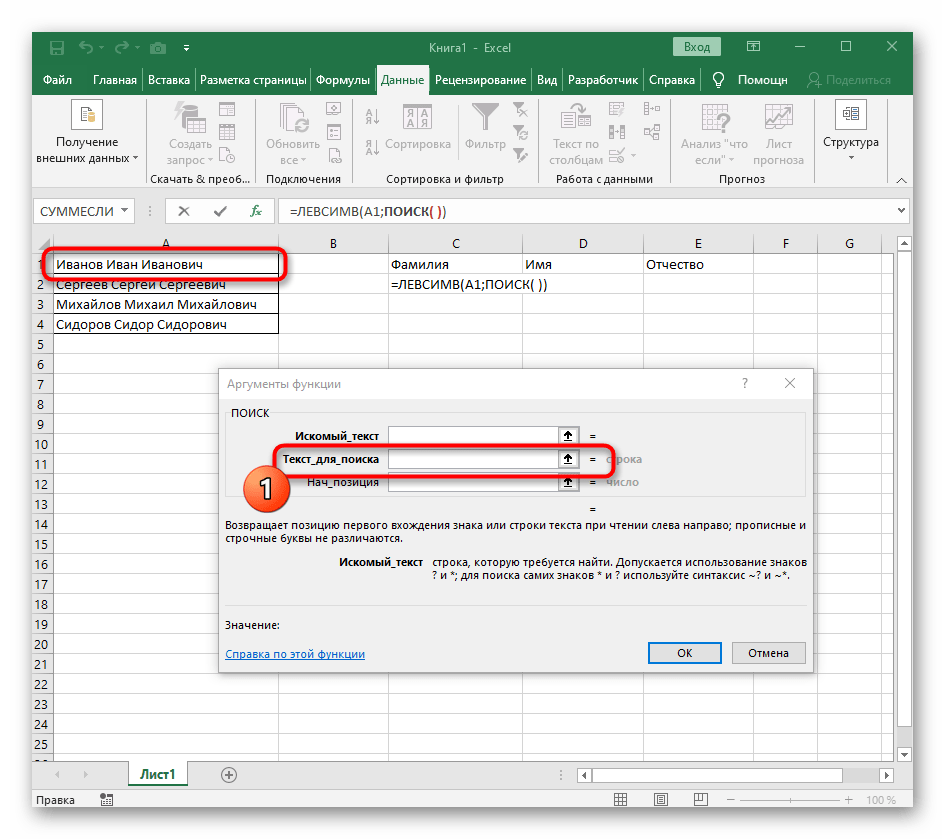
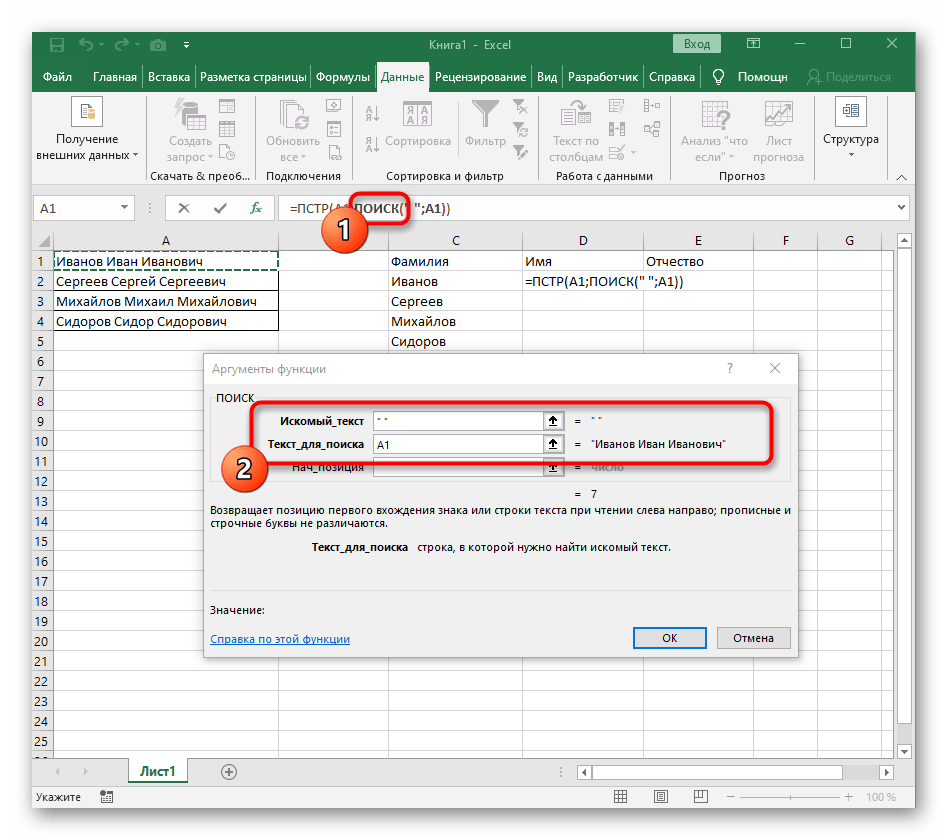
- V poli "Hľadaný_text" jednoducho zadajte medzeru alebo používaný oddeľovač, pretože to pomôže pochopiť, kde končí slovo. V "Text_na_hľadanie" uveďte tú istú spracovávanú bunku.
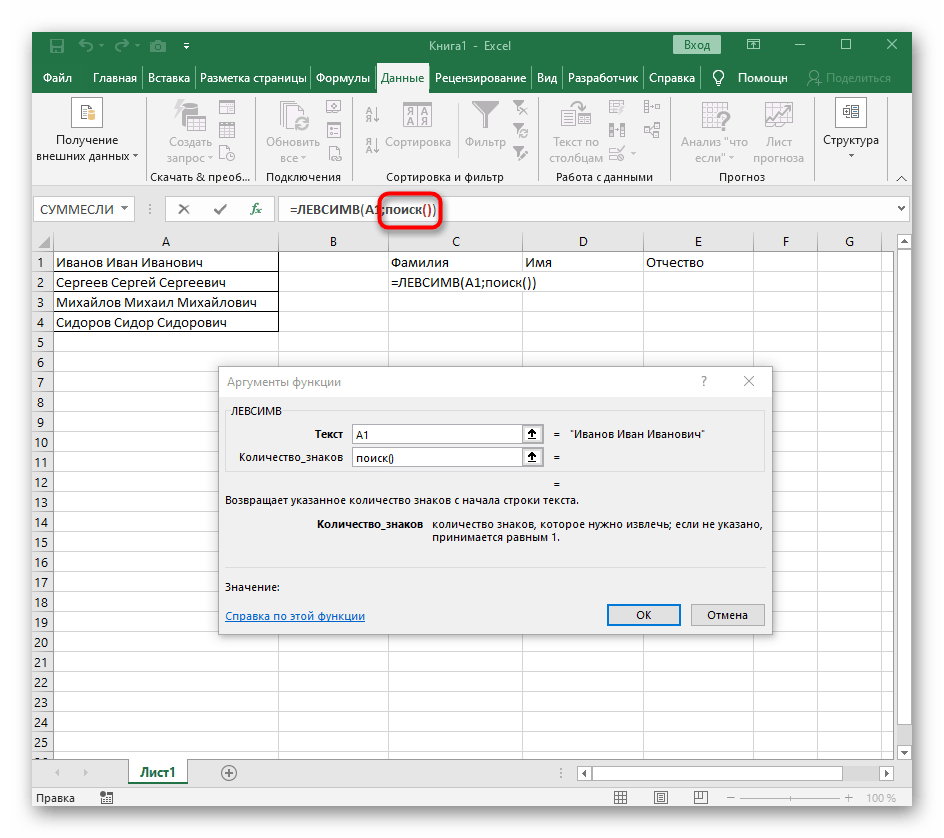
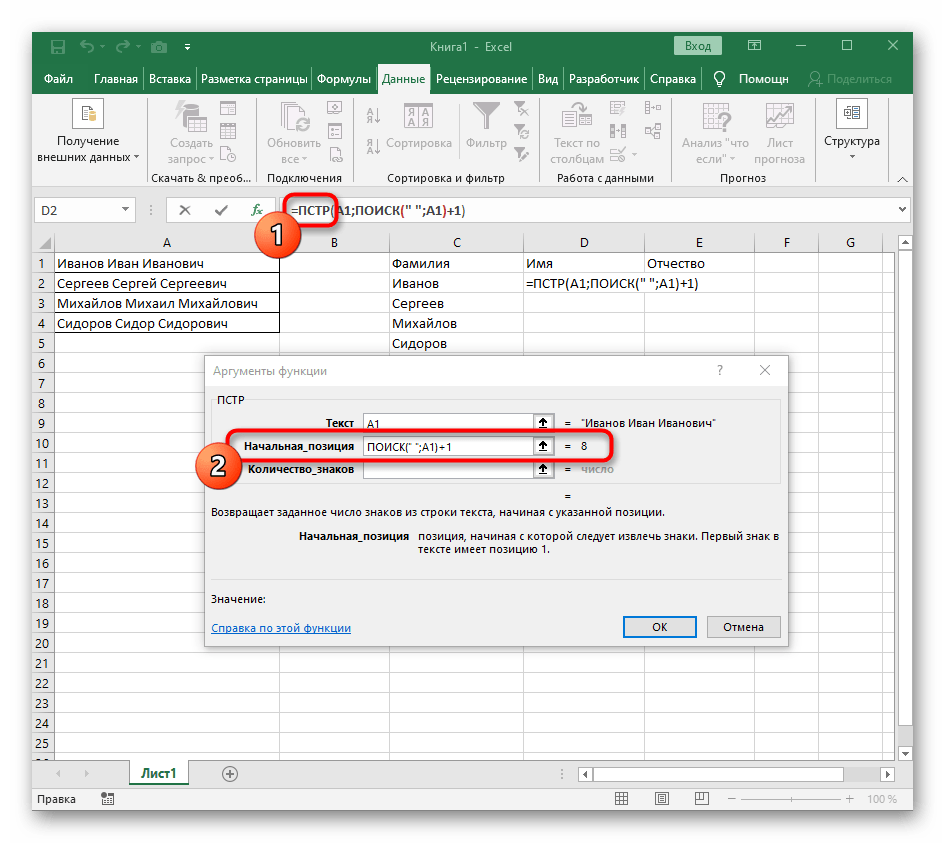
- Kliknite na prvú funkciu, aby ste sa k nej vrátili, a na konci druhého argumentu pridajte
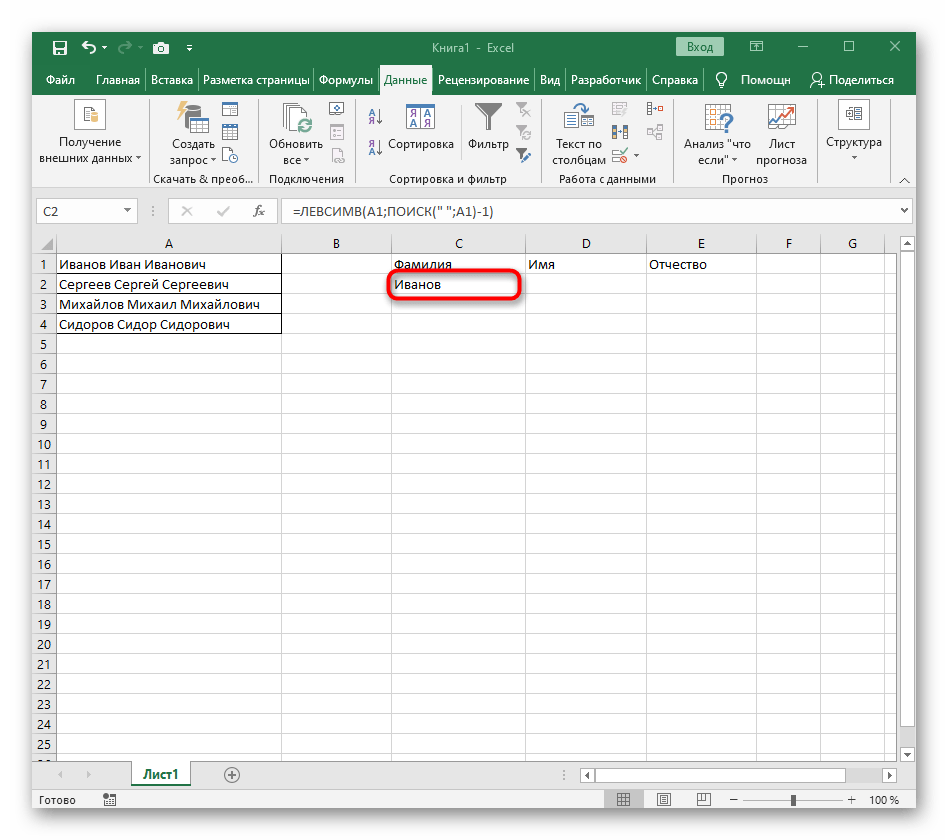
-1. To je potrebné, aby vzorec "NÁJDI" zohľadnil nie hľadanú medzeru, ale znak pred ňou.Ako je vidieť na nasledujúcom snímku obrazovky, výsledkom je priezvisko bez akýchkoľvek medzier, čo znamená, že zostavenie vzorcov bolo vykonané správne. - Zatvorte editor funkcií a uistite sa, že slovo sa správne zobrazuje v novej bunke.
- Držte bunku v pravom dolnom rohu a potiahnite ju nadol na potrebný počet riadkov, aby ste ju natiahli. Takto sa dosadia hodnoty iných výrazov, ktoré je potrebné rozdeliť, a vykonanie vzorca prebieha automaticky.
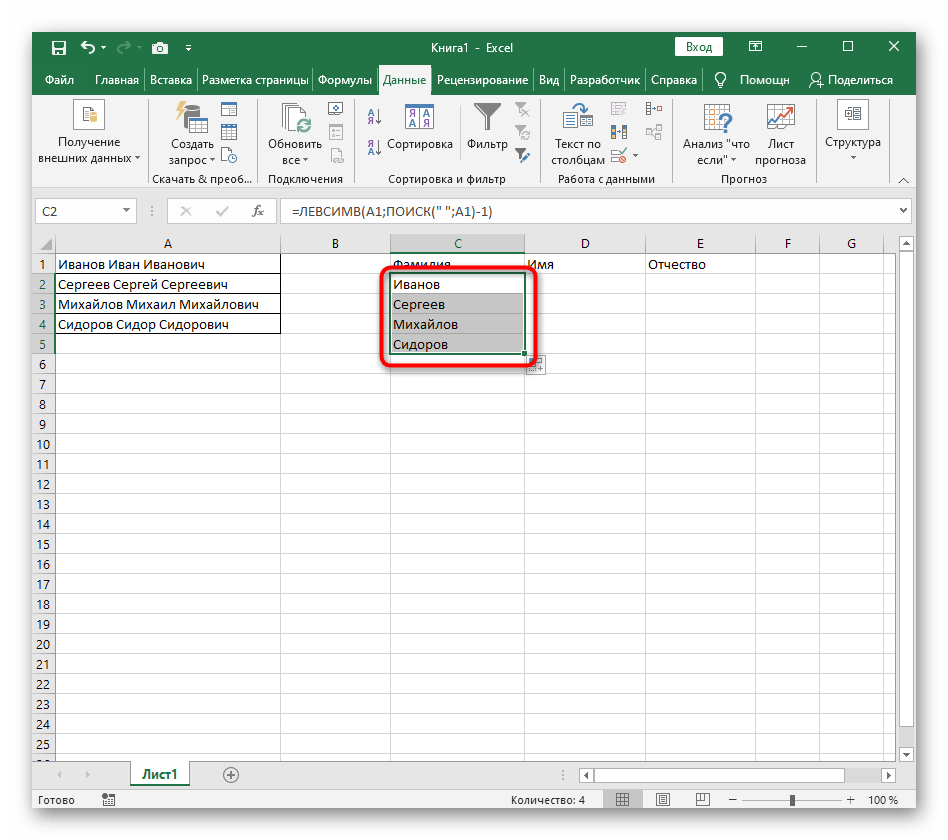
Úplne vytvorený vzorec má tvar =ĽAVÝ(A1;NÁJDI(" ";A1)-1), vy ho môžete vytvoriť podľa vyššie uvedeného návodu alebo vložiť tento, ak podmienky a oddeľovač vyhovujú. Nezabudnite nahradiť spracovávanú bunku.
Krok 2: Rozdelenie druhého slova
Najťažšie je rozdeliť druhé slovo, ktorým je v našom prípade meno. Je to spôsobené tým, že je obklopené medzerami z oboch strán, preto bude potrebné zohľadniť obidve pri vytváraní rozsiahleho vzorca pre správny výpočet pozície.
- V tomto prípade sa hlavným vzorcom stane
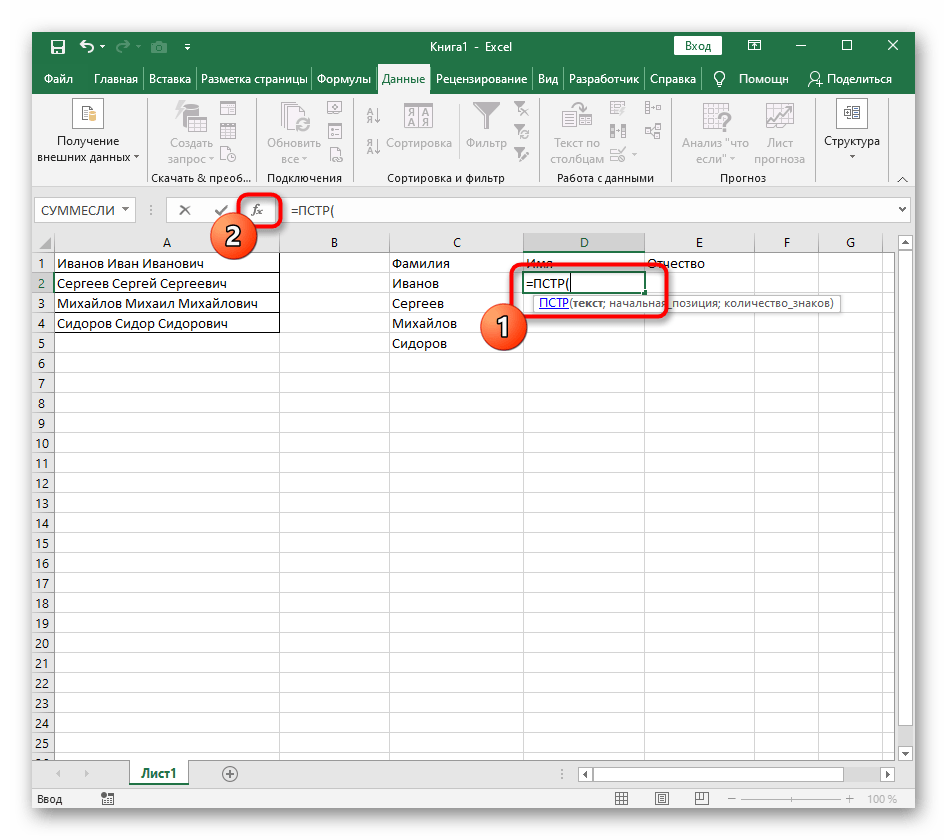
=MID(— zapíšte ho v tejto podobe a potom prejdite k oknu nastavenia argumentov. - Tento vzorec bude hľadať požadovaný riadok v texte, pričom ako text vyberieme bunku s nápisom na rozdelenie.
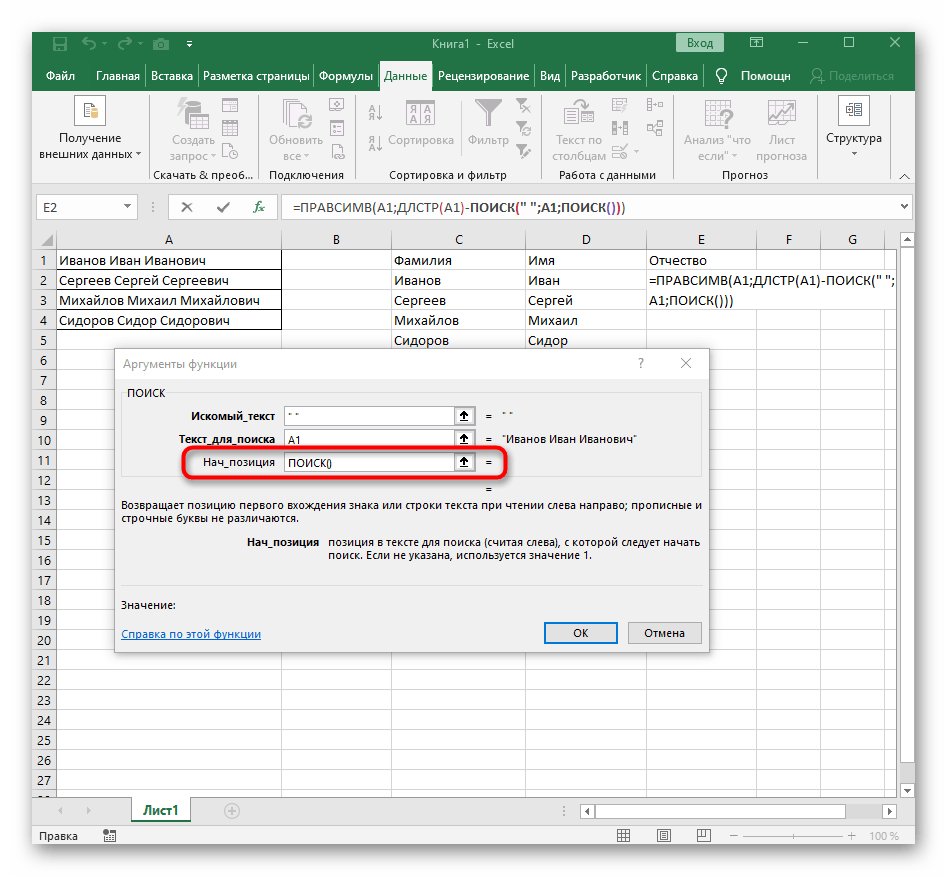
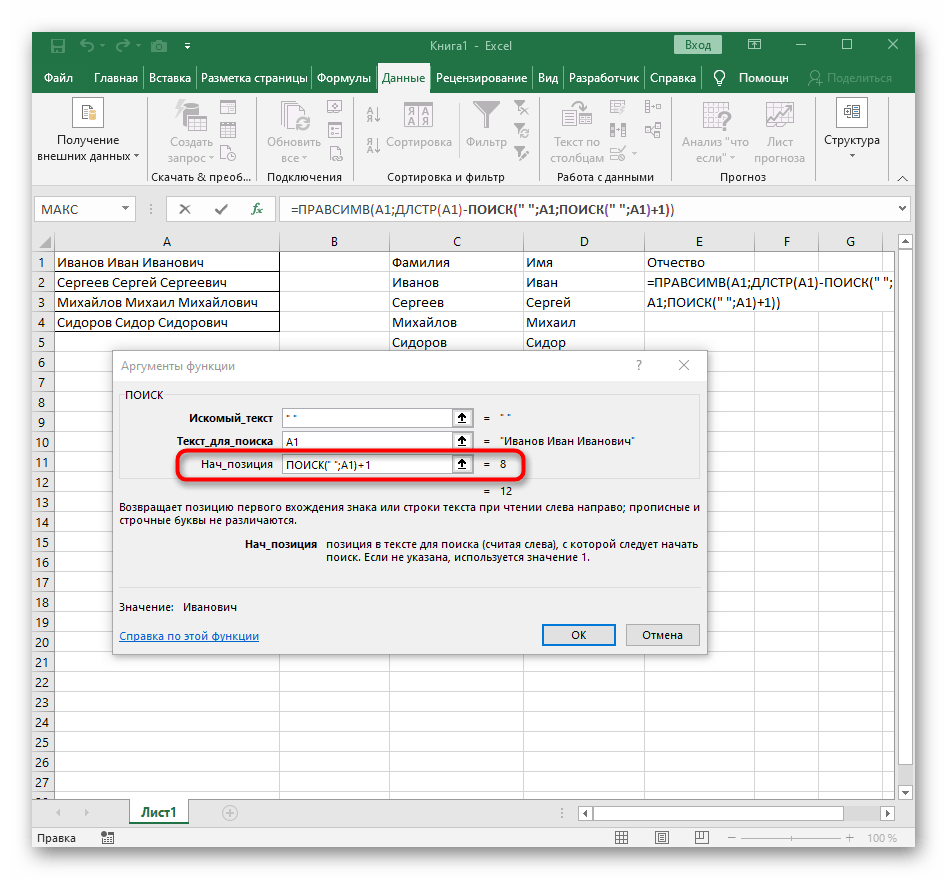
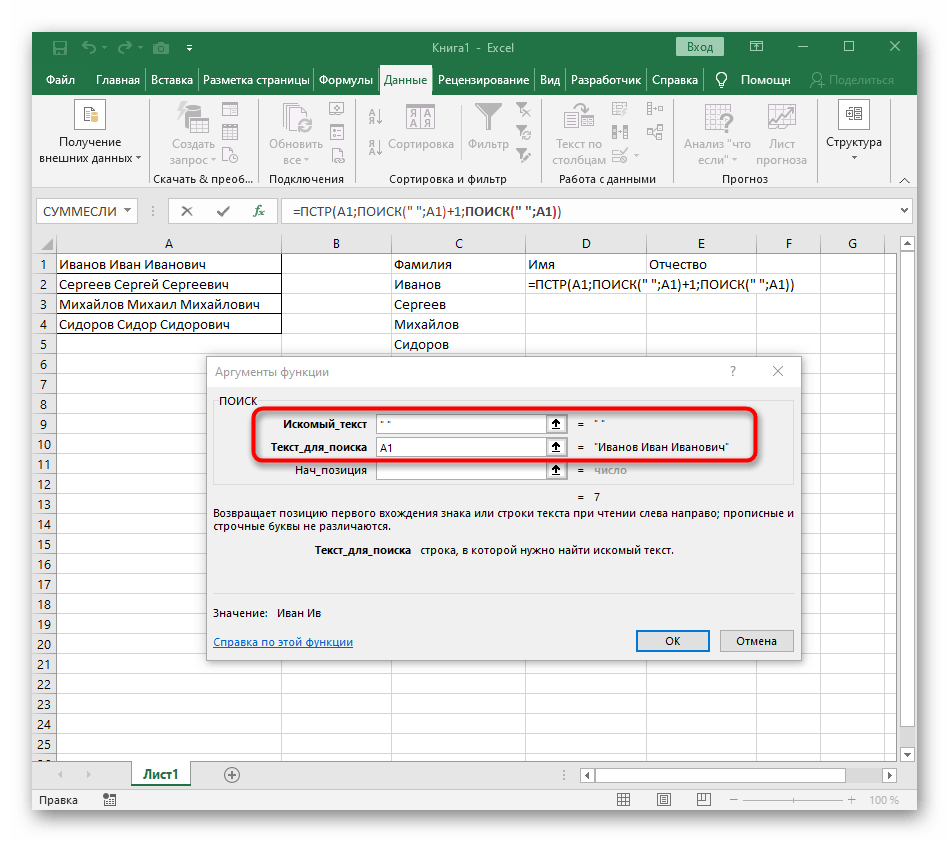
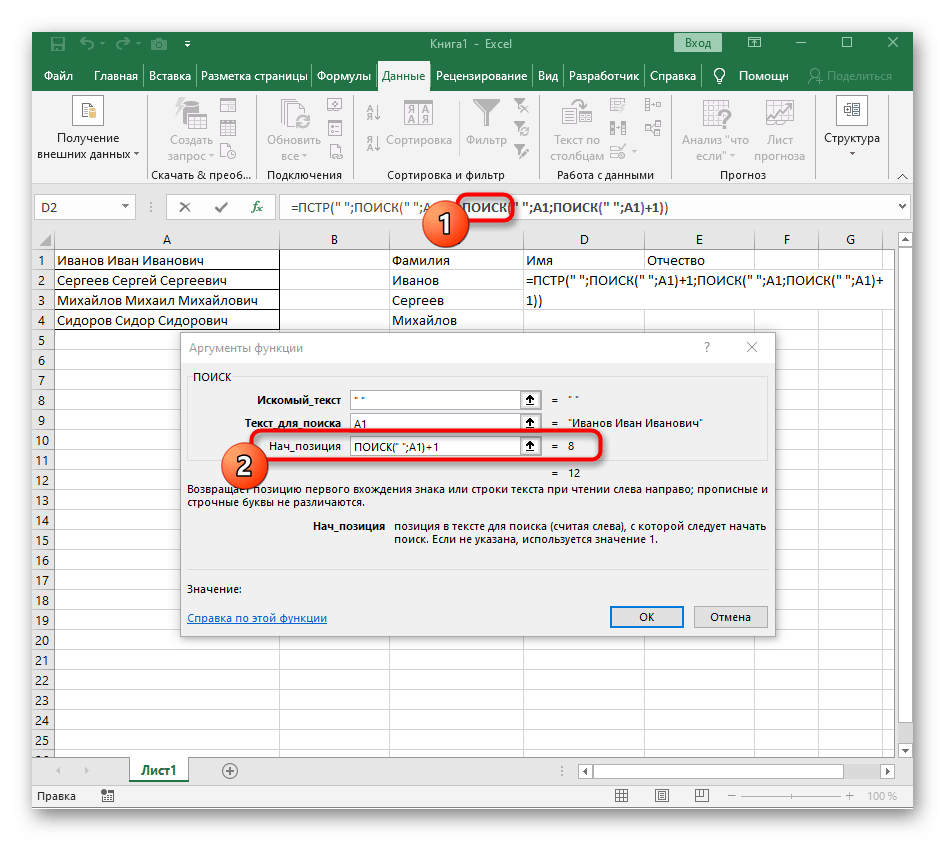
- Počiatočnú pozíciu riadku bude potrebné určiť pomocou už známej pomocnej funkcie
NÁJDI(). - Po vytvorení a prechode k nej vyplňte presne tak, ako to bolo ukázané v predchádzajúcom kroku.Ako hľadaný text použite oddeľovač a bunku určte ako text na vyhľadávanie.
- Vráťte sa k predchádzajúcej formule, kde pridajte k funkcii "HĽADANIE"
+1na konci, aby ste začali počítať od nasledujúceho znaku po nájdenom prázdnom mieste. - Teraz už formula môže začať vyhľadávanie reťazca od prvého znaku mena, ale zatiaľ ešte nevie, kde ho skončiť, preto do poľa "Počet_znakov" znova napíšte formulu
HĽADANIE(). - Prejdite k jej argumentom a vyplňte ich už známy spôsobom.
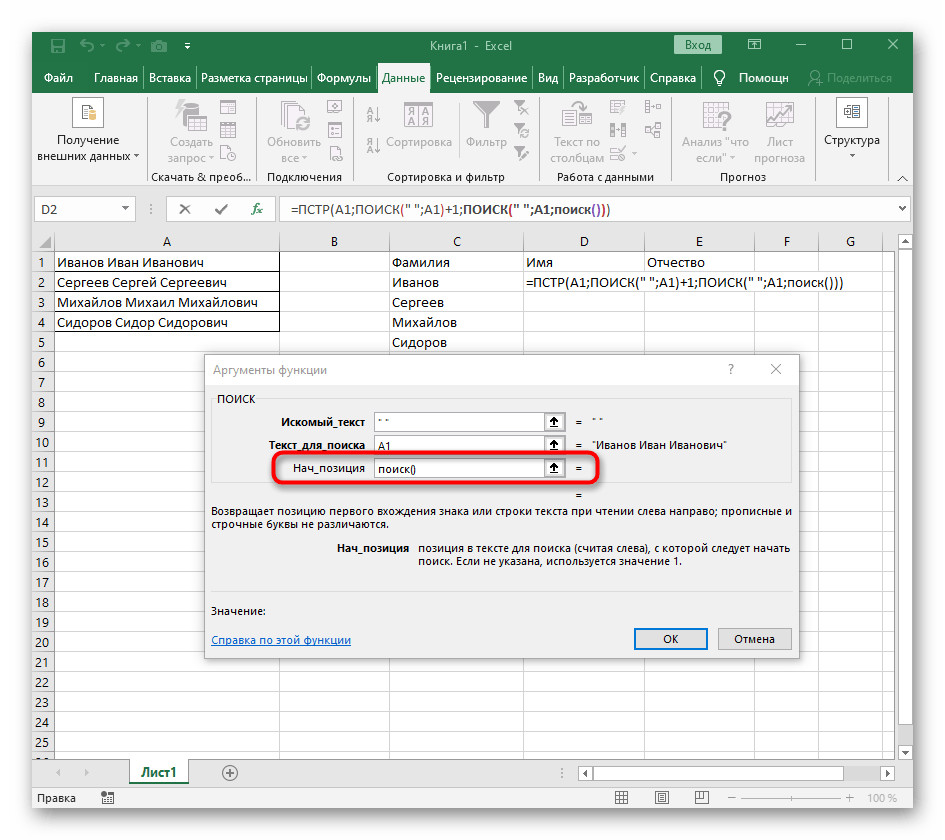
- Predtým sme nezohľadnili počiatočnú pozíciu tejto funkcie, ale teraz tam treba tiež napísať
HĽADANIE(), pretože táto formula by mala nájsť nie prvé, ale druhé prázdne miesto. - Prejdite k vytvorenej funkcii a vyplňte ju rovnakým spôsobom.
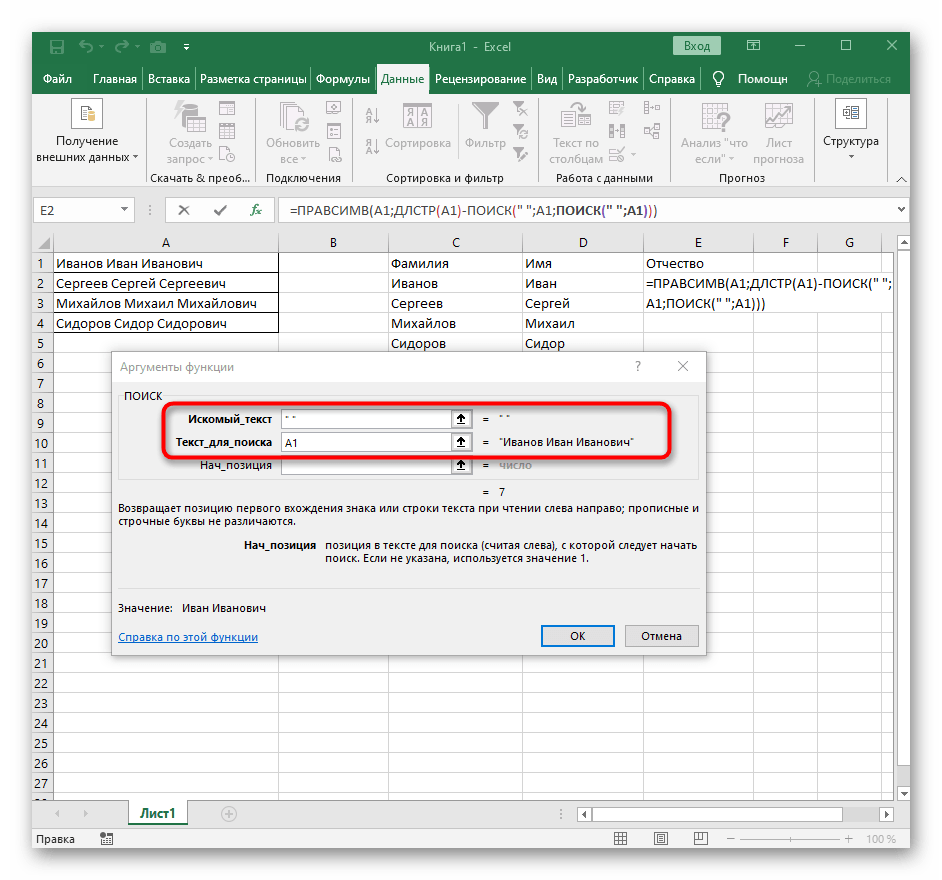
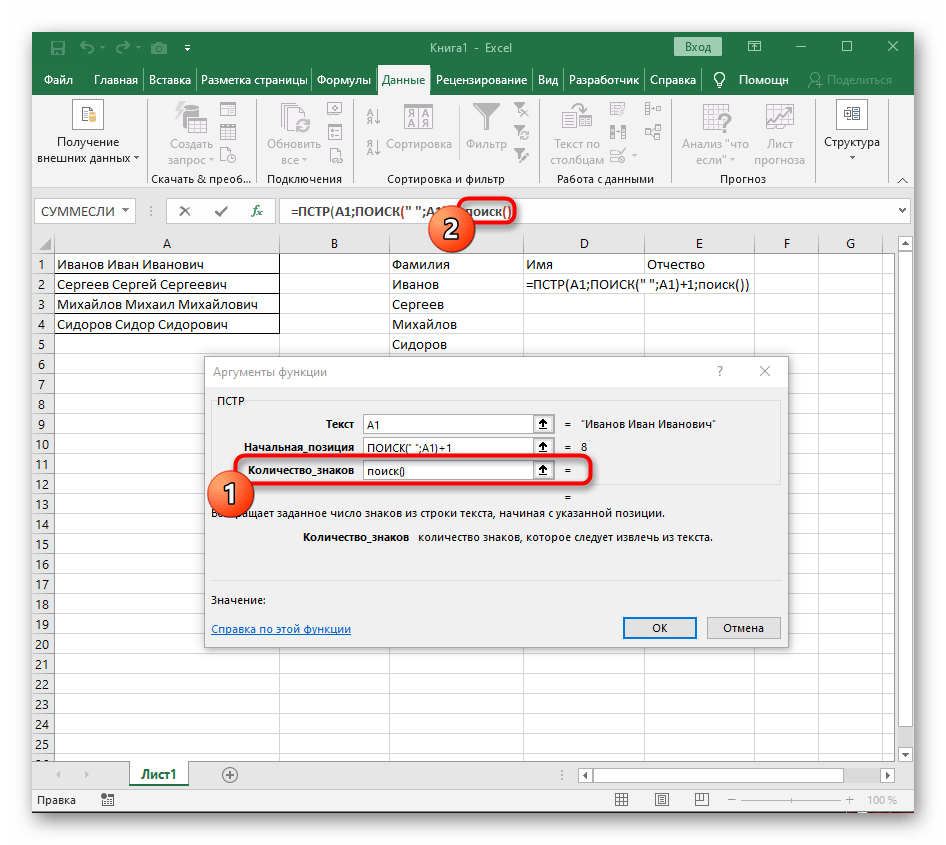
- Vráťte sa k prvému
"HĽADANIU"a doplňte do "Poč_pozícia"+1na konci, pretože na vyhľadávanie reťazca nie je potrebné prázdne miesto, ale nasledujúci znak. - Kliknite na koreň
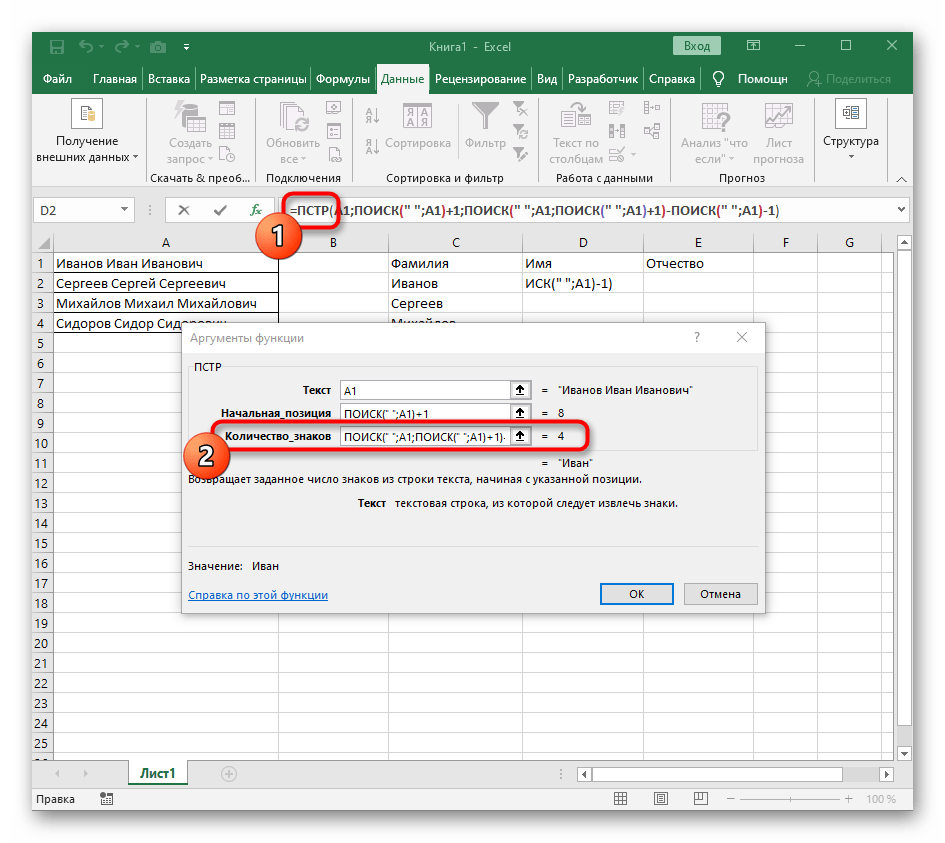
=ČASTOa umiestnite kurzor na koniec reťazca "Počet_znakov". - Doplňte tam výraz
-HĽADANIE(" ";A1)-1)na dokončenie výpočtov prázdnych miest. - Vráťte sa k tabuľke, natiahnite formulu a uistite sa, že slová sa zobrazujú správne.
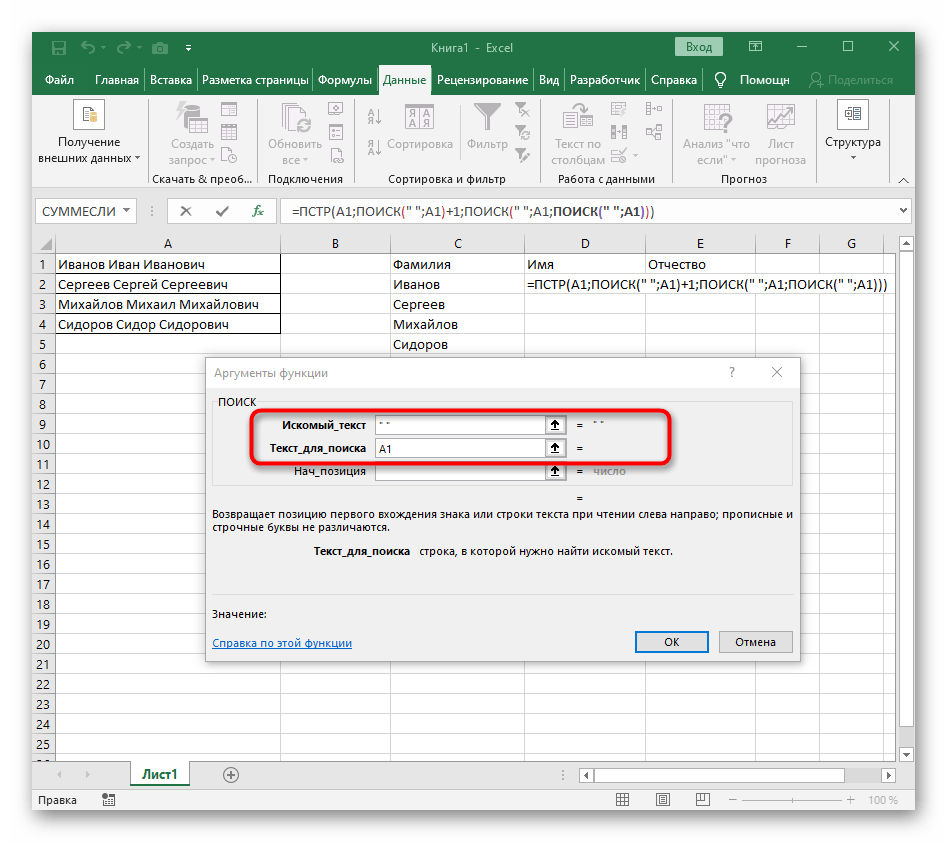
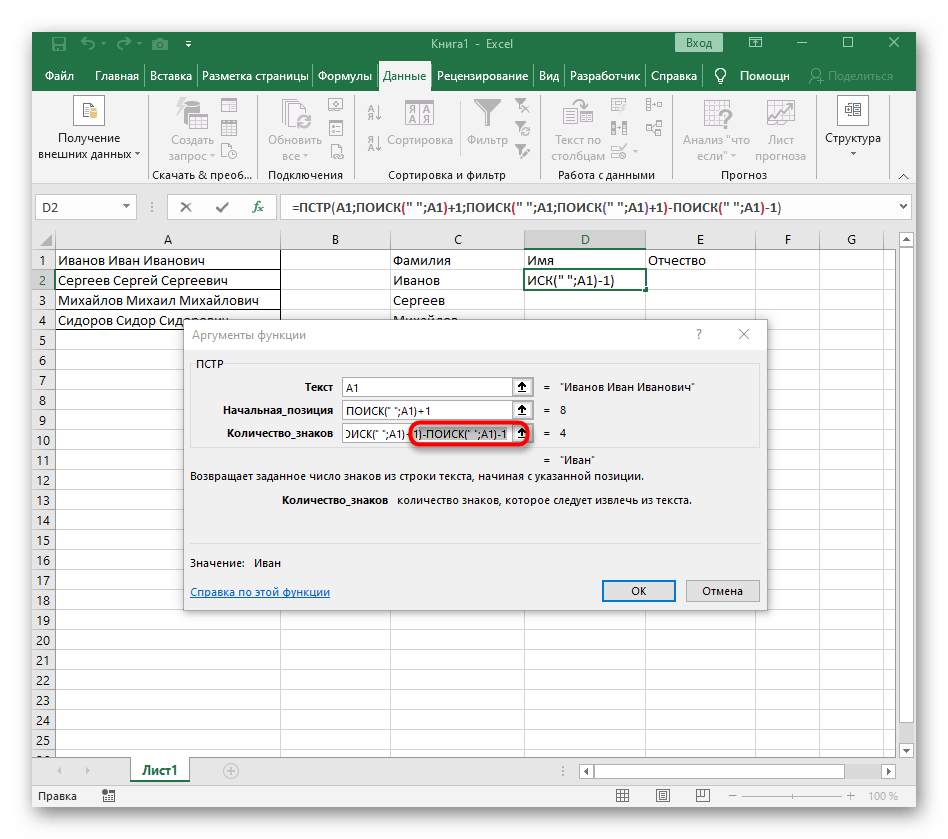
Formula sa stala veľkou a nie všetci používatelia rozumejú, ako presne funguje. Ide o to, že na vyhľadávanie reťazca bolo potrebné použiť niekoľko funkcií, ktoré určovali počiatočné a konečné pozície prázdnych miest, a potom sa od nich odčítal jeden znak, aby sa tieto prázdne miesta nezobrazovali.Nakoniec je vzorec takýto: =PODĽA(A1;NAJDI(" ";A1)+1;NAJDI(" ";A1;NAJDI(" ";A1)+1)-NAJDI(" ";A1)-1). Použite ho ako príklad, pričom nahraďte číslo bunky s textom.
Krok 3: Rozdelenie tretieho slova
Posledný krok našich inštrukcií zahŕňa rozdelenie tretieho slova, čo vyzerá približne rovnako ako to, čo sa dialo s prvým, ale celkový vzorec sa trochu mení.
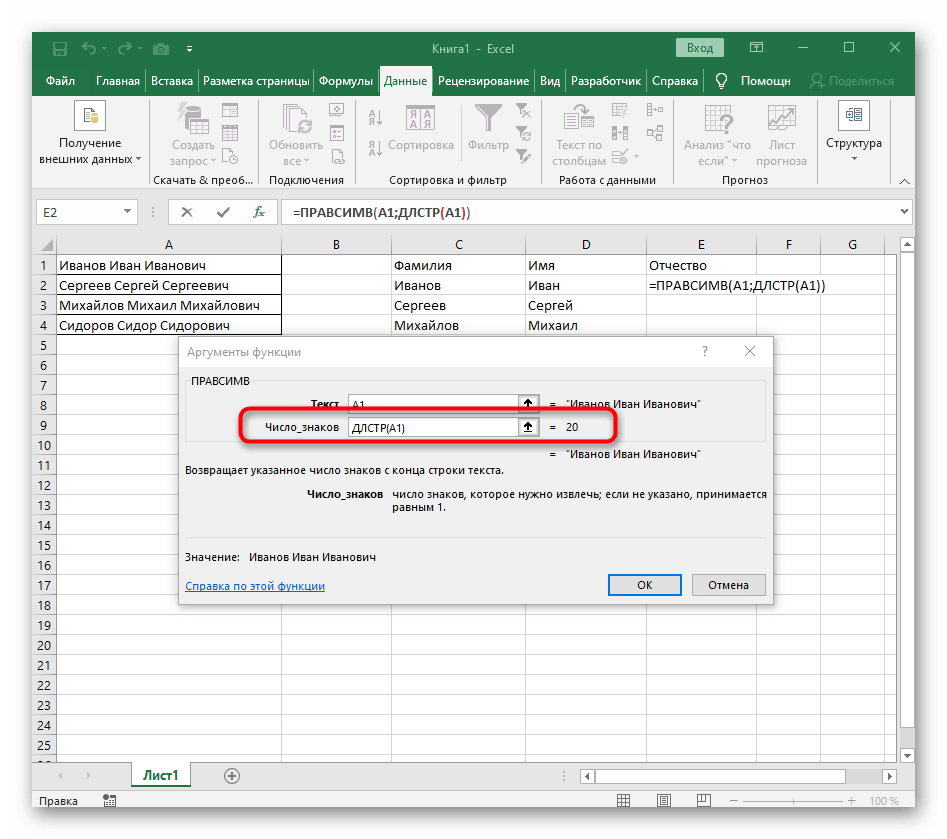
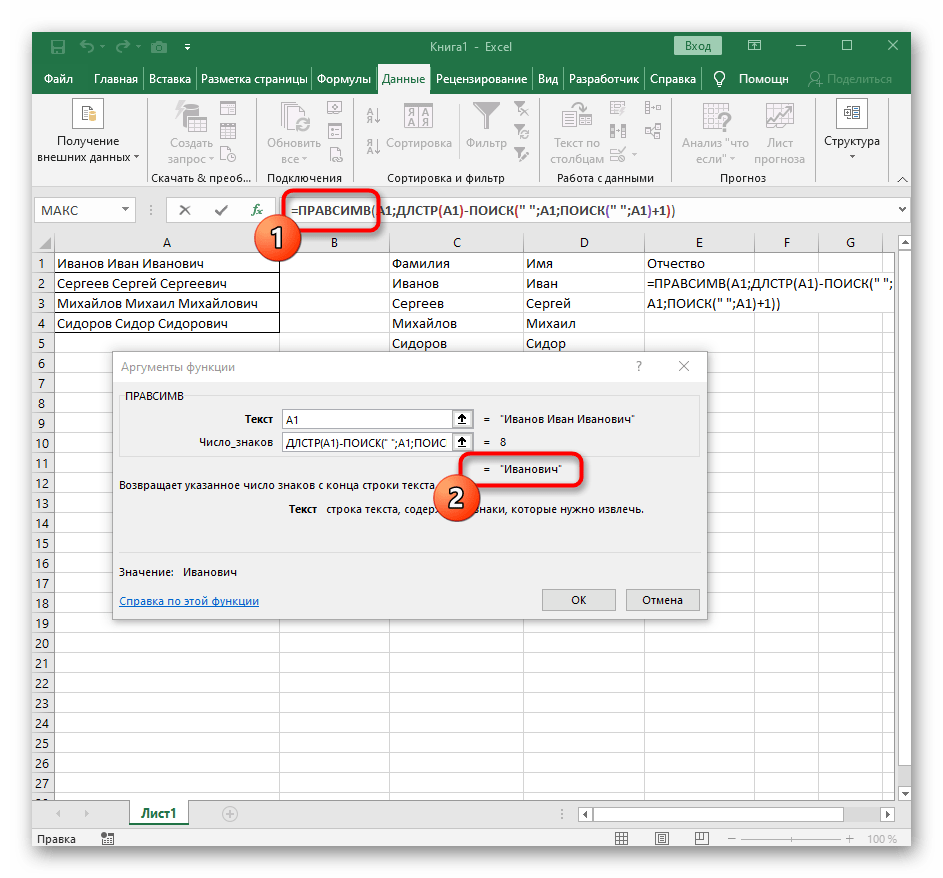
- Do prázdnej bunky pre umiestnenie budúceho textu napíšte
=PRAVÝ(a prejdite k argumentom tejto funkcie. - Ako text uveďte bunku s nápisom na rozdelenie.
- Tentokrát pomocná funkcia na vyhľadanie slova sa nazýva
DĹŽKA(A1), kde A1 — tá istá bunka s textom. Táto funkcia určuje počet znakov v texte, a nám zostáva vybrať len vhodné. - Na to pridajte
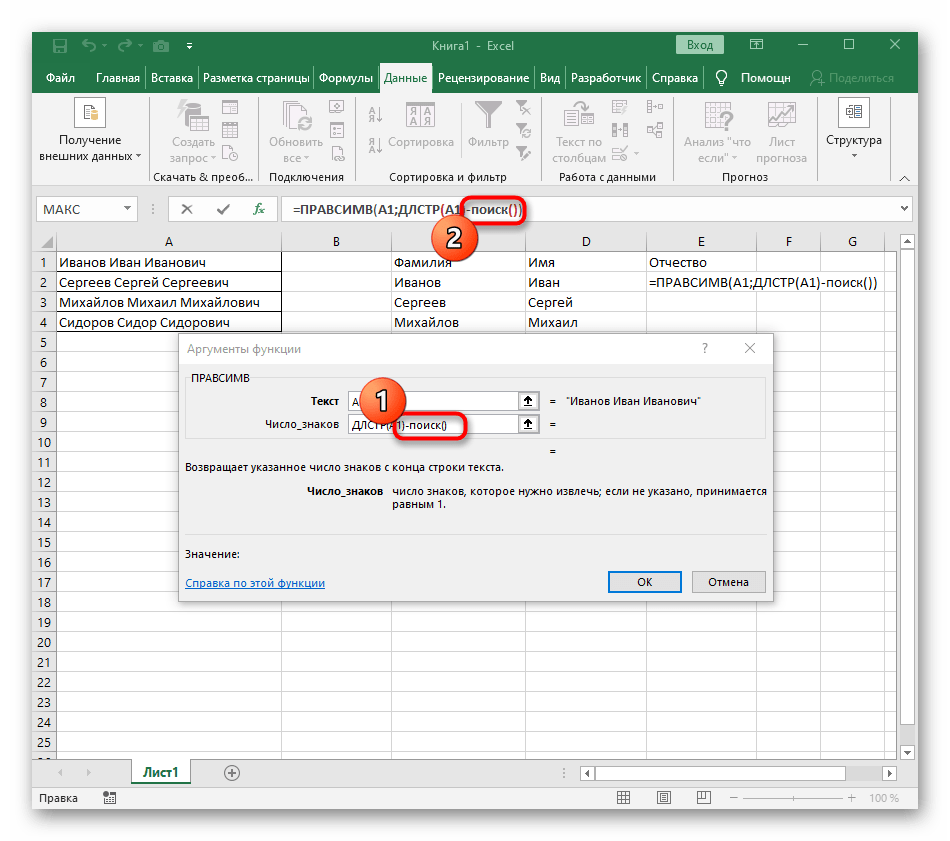
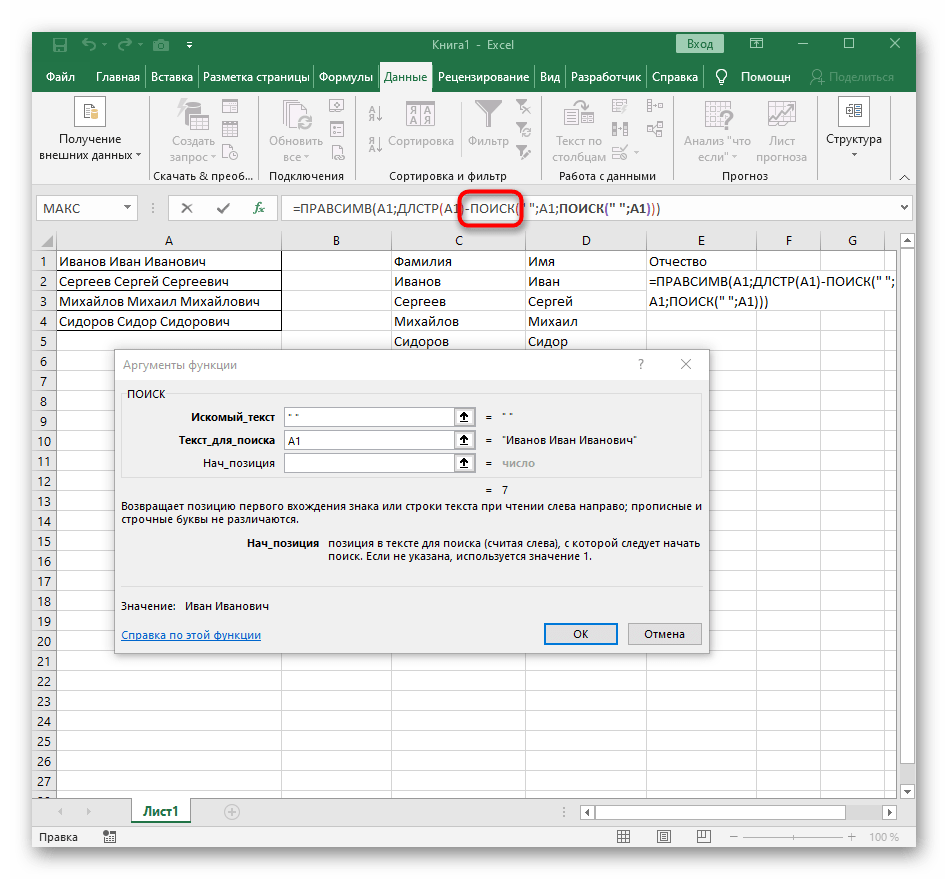
-NAJDI()a prejdite k úprave tohto vzorca. - Zadajte už známy štruktúru na vyhľadanie prvého oddeľovača v riadku.
- Pridajte pre počiatočnú pozíciu ešte jeden
NAJDI(). - Uveďte mu tú istú štruktúru.
- Vráťte sa k predchádzajúcemu vzorcu "NAJDI".
- Pridajte pre jeho počiatočnú pozíciu
+1. - Prejdite k základnému vzorcu
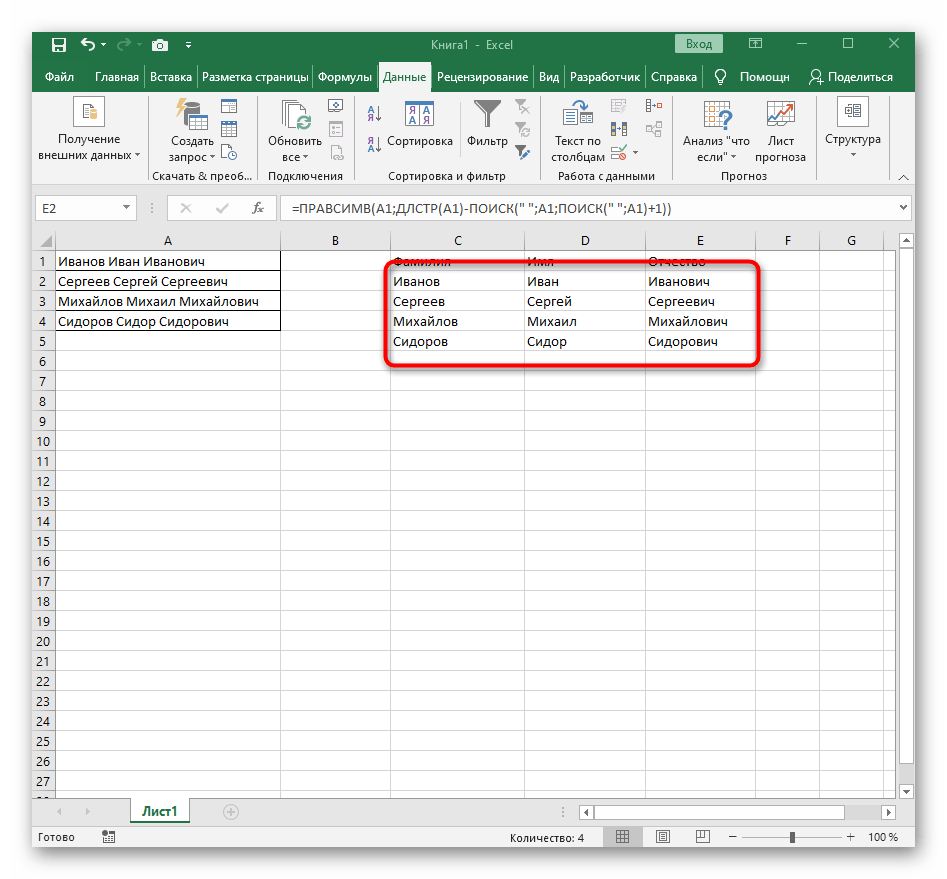
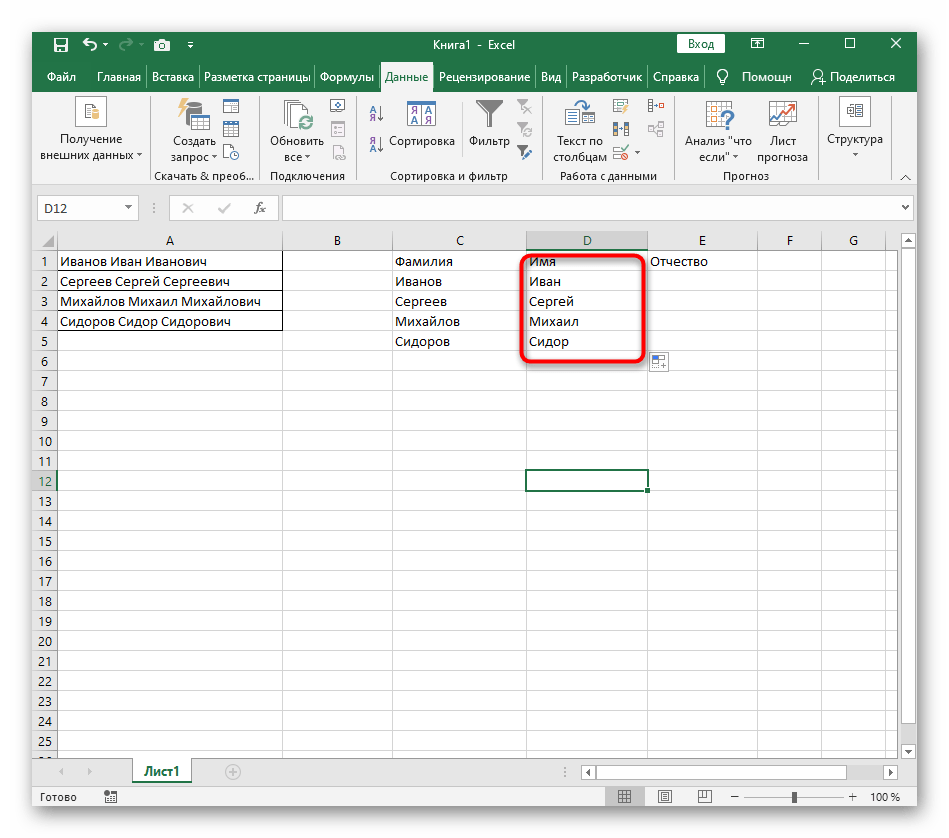
PRAVÝa uistite sa, že výsledok sa zobrazuje správne, a až potom potvrďte vykonané zmeny. Celkový vzorec v tomto prípade vyzerá ako=PRAVÝ(A1;DĹŽKA(A1)-NAJDI(" ";A1;NAJDI(" ";A1)+1)). - Nakoniec na nasledujúcom snímku obrazovky vidíte, že všetky tri slová sú správne rozdelené a nachádzajú sa vo svojich stĺpcoch. Na to bolo potrebné použiť rôzne vzorce a pomocné funkcie, ale to umožňuje dynamicky rozširovať tabuľku a nemusíte sa obávať, že každý raz budete musieť text znovu rozdeľovať. V prípade potreby jednoducho rozšírte vzorec jeho presunutím nadol, aby sa nasledujúce bunky automaticky zahrnuli.